
概述
Agile Query 聚合函数不同于SQL 中的聚合函数,SQL 中的聚合函数只能应用在单表或构建的单个动态数据集中,而Agile Query 中的聚合函数则可以应用在多表, 且可以叠加过滤或排序等查询特性(算术运算时,也可以将不同维度或不同表中的数据聚合后进行运算),最终由Agile Query 编译器编译为不同数据库中的SQL, 编译过程中会最大程度的降低原生查询的数量(即读取原始数据库表中的查询,也是产生大量I/O 操作的动作,对查询性能的影响较大)。
Agile Query 中的聚合函数分为四大类:
- 简单聚合函数,类似SQL 的聚合函数,用于基础的聚合统计,例如: SUM、AVG 等。
- 过滤聚合函数,基于的简单过滤规则或聚合后的规则进行计算,进行例如:COUNT_IF、SUM_IF 等。
- 分组聚合函数:用于实现不同维度的数据进行运算,例如:GROUP_AVG、GROUP_COUNT 等。
- 领域函数:基于抽象数据分析模式,实现领域内的通用统计方法,例如:GROWTH_OF、SEGMENT 等。
1. 简单聚合函数系列
聚合函数是一类用于对一组数据执行计算并返回单个结果的函数,帮助用户在进行数据分析时从大量数据中提取有意义的信息,以便做出更好的决策。
SQL 中的标准聚合函数包括:AVG、COUNT、SUM、MAX、MIN,STDDEV、VAR,这类聚合函数从技术限制的角度分类可分为三类,MIN、MAX 分为一类,
这些聚合函数对分组都不敏感。COUNT 分为一类,对分组和连接比较敏感,不同的连接方式或分组方式都对结果产生较大影响,AVG、STDDEV、VAR 分为一类,
这类聚合聚合除了对分组和连接敏感外,而且不能进行简单的二次聚合,例如:统计全校学生的平均成绩,不能直接在每个班级的平均成绩的基础上再进行 AVG 运算。
正确的计算方法是分子和分母累加后再进行运算,例如: SUM(students.score) / COUNT(students.id)。
由于上述SQL 的技术上限制,Agile Query 中的简单聚合函数在编译过程中进行了优化,COUNT 函数在二次聚合时,会转换为 SUM 函数,AVG、STDDEV、VAR 这类函数,会自动拆解为分子和分母,再聚合时,再依据计算规则重新计算。
在多表聚合统计时,不同关联关系对输出结果也会产生影响,详细介绍请参考SQL 中的断层和扇形陷阱 一文,些处不作过多解释。 Agile Query 也依据不同的关联关系推理出正确的连接方式,并以拆分子查询的形式确保统计结果的正确性,下面以零售数据为例,以不同的视角详细介绍一下Agile Query 简单聚合函数。
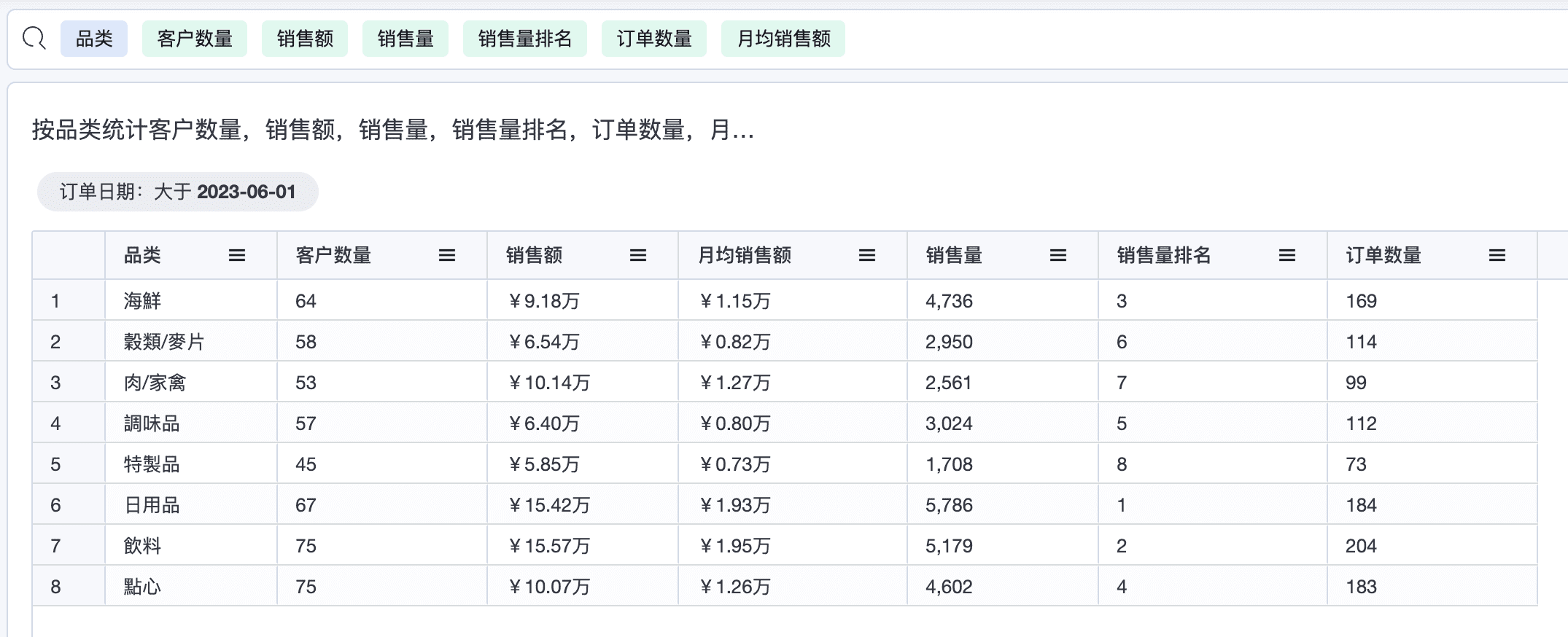
1.1 按品类统计客户数量,销售额,销售量,销售量排名,订单数量
AVG(
GROUP_SUM(
order_details.quantity * order_details.unit_price,
TO_MONTH(orders.order_date)
)
)
RANK(
SUM(order_details.quantity)
)
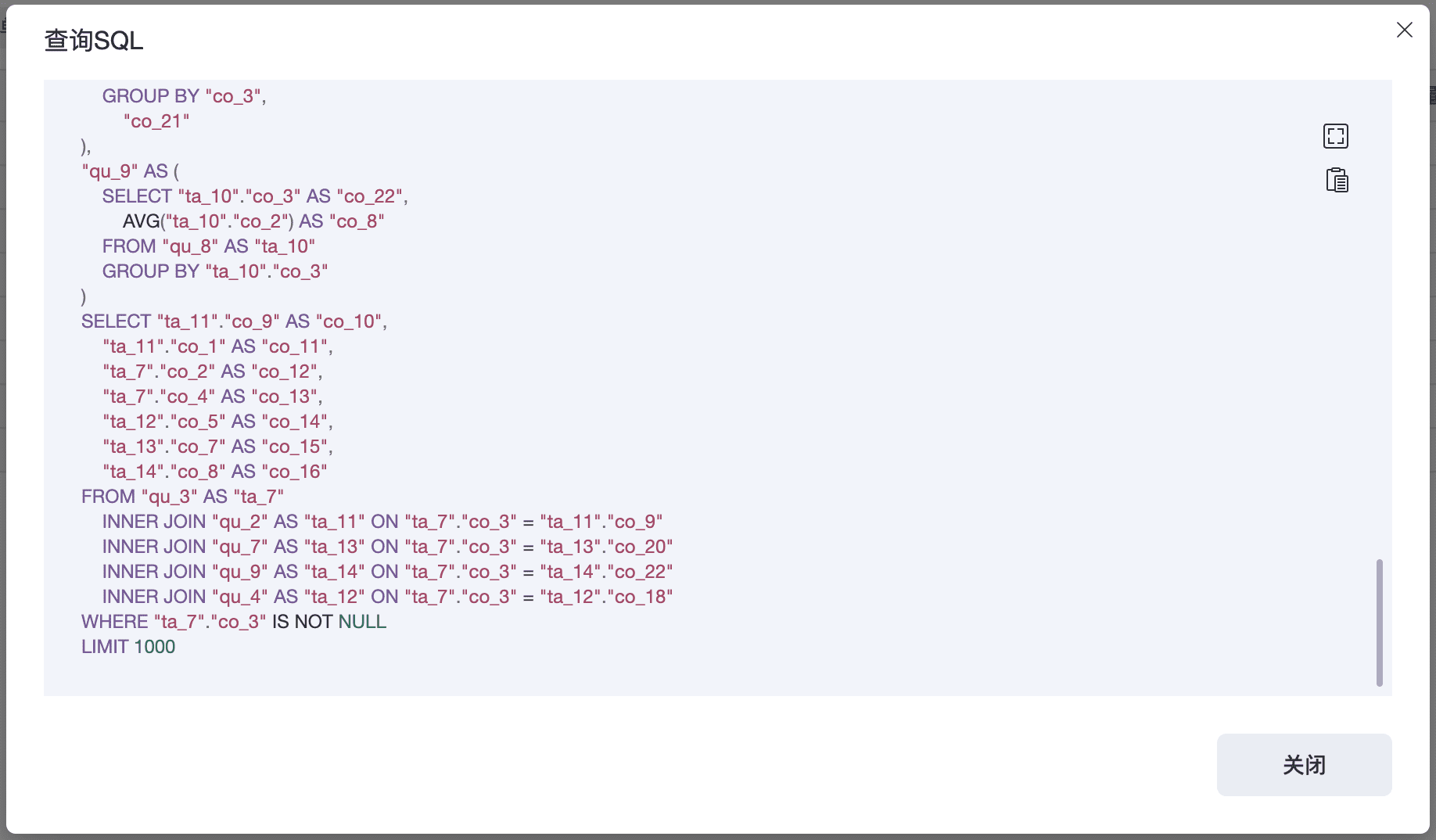
上述查询是一个简单的聚合统计,但由于关联关系会导致整个SQL 复杂一下,因为品类和订单,品类与客户之间是多对多的关系,一段时间内,一个品类可拥有多个客户, 一个客户也可以购买多个品类下的商品,所以简单机械的连接表后进行聚合计算,输出的结果就会产生错误,需要产生大量的子查询,在每个子查询中聚合数据, 并按一致的维度聚合后再进行连接。
上述示例中,单个聚合值的计算都比较简单,数据工程师编写SQL 的效率也会非常高,但这些些聚合值按指定的维度进行聚合后,同时输出统计结果就使得这个查询变得复杂的多。
1.2 统计指标不变,切换为供应商,和商品维度
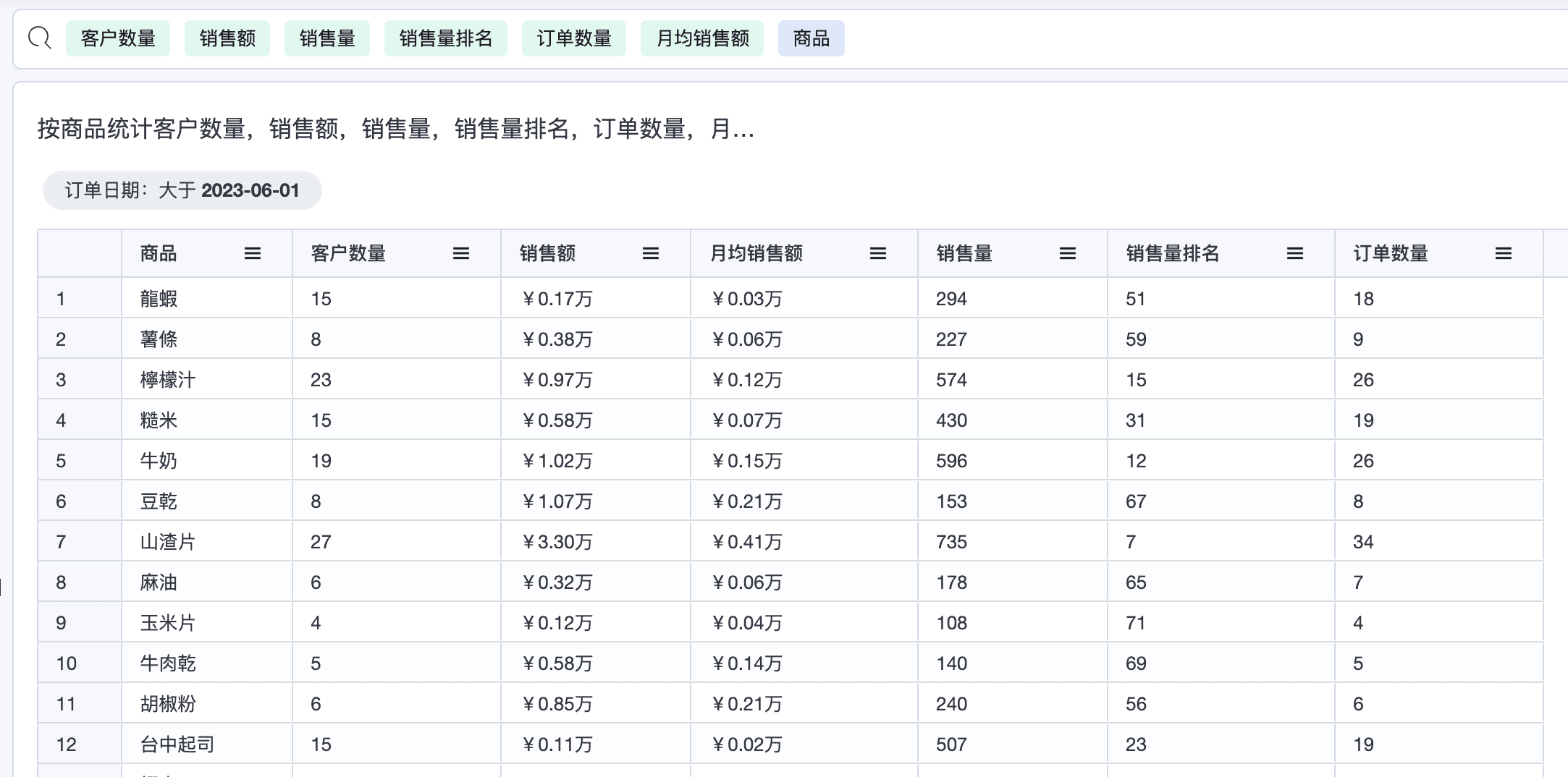
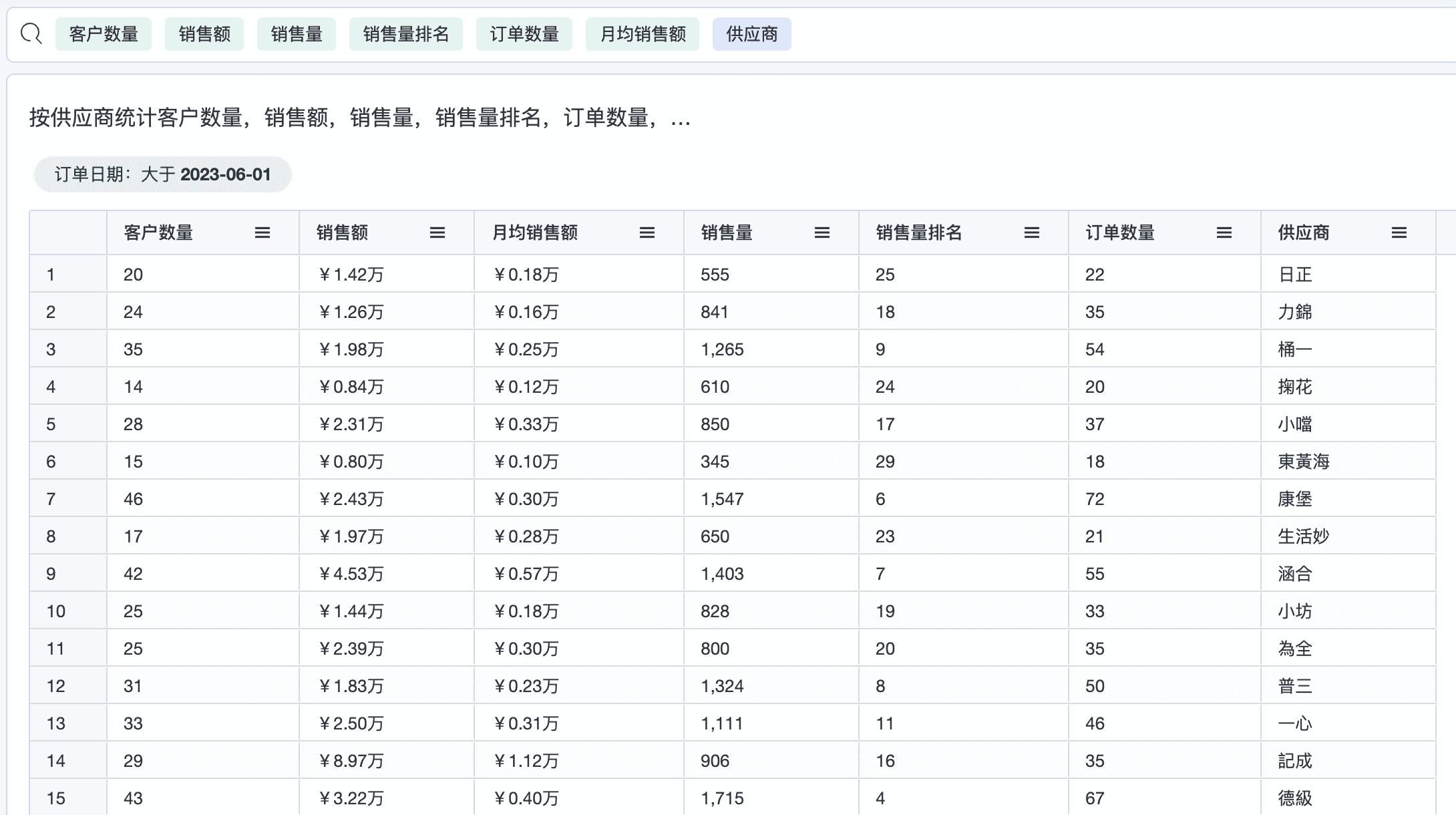
上述示例中,切换了不同的维度,而这些维度涉及了不同的表,但关联系统与品类是一致的,与聚合表之间的关系都是多对多,但连接方式则完全不同, 如果纯手工写SQL 查询,会产生大量重复的SQL,而使用Agile Query 则不需要,它会依据图算法智能推理出连接方式,并拆分多个子查询,提升了数据分析效率。
1.3 始终确保数据准确性
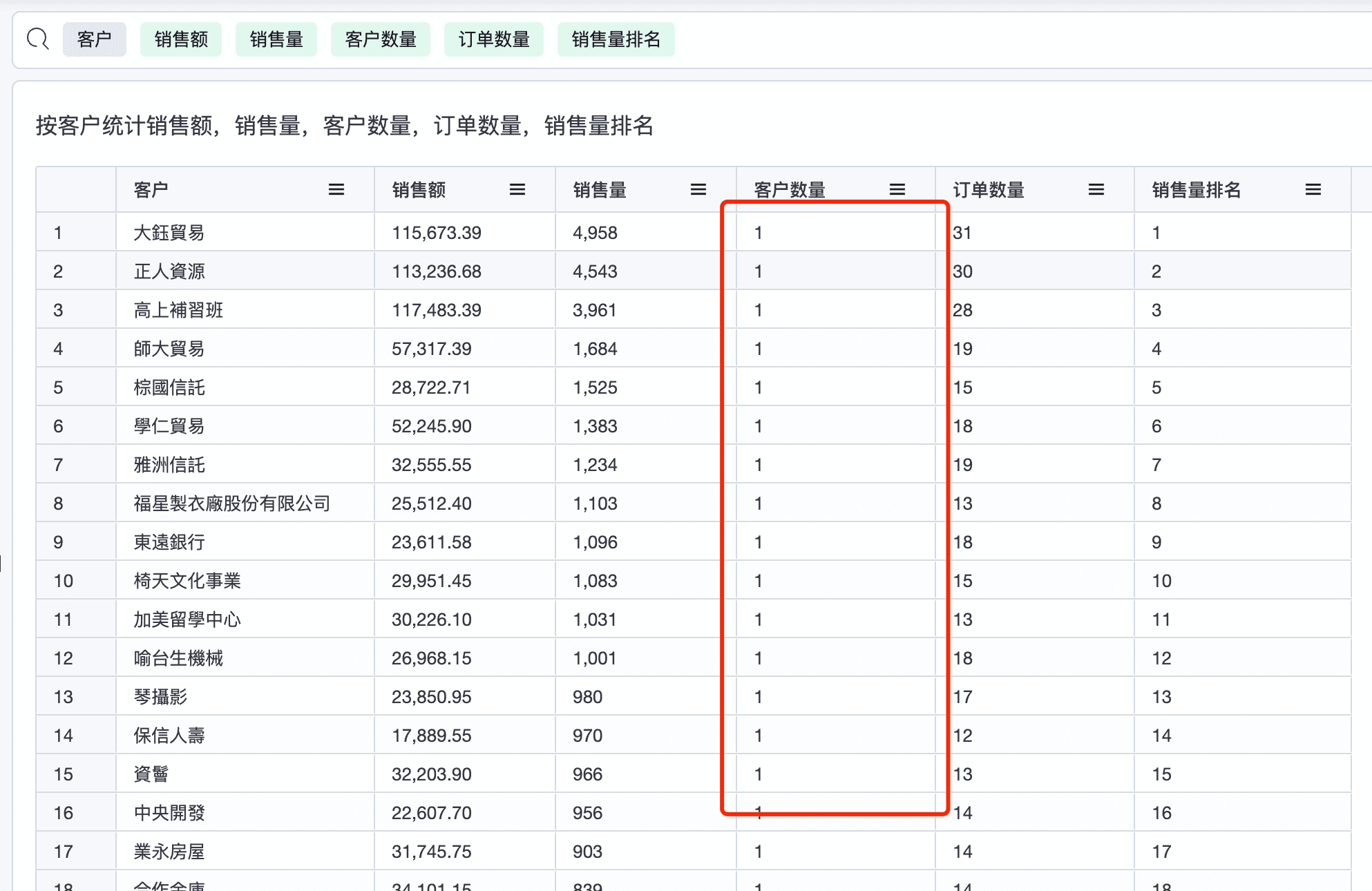
上述示例是一个非常正常的查询,以客户分组统计客户的数量,从业务视角理解是一个不合理的查询,但Agile Query 依然保证了数据理解的正确性。
2. 过滤聚合函数系列
过滤聚合函数在实际场景中被频繁使用,例如:统计某个品类或某几个品类的销售额(客户数量、销售量等),统计某些区域的客户数量等,还会在算术运算中也会频繁使用, 例如:统计某些品类的销售额占总体销售额的比例,购买3 次以上的客户占总体客户的比例等。从字面上理解,上述统计可以通过过滤规则的形式进行统计, 但SQL 中的过滤规则是全局过滤的,例如:统计每个品类的 近3 个月的销售额,近6 个月的销售额,近12 个月的销售额,通过过滤的等式进行查询则无法实现,如下图所示:
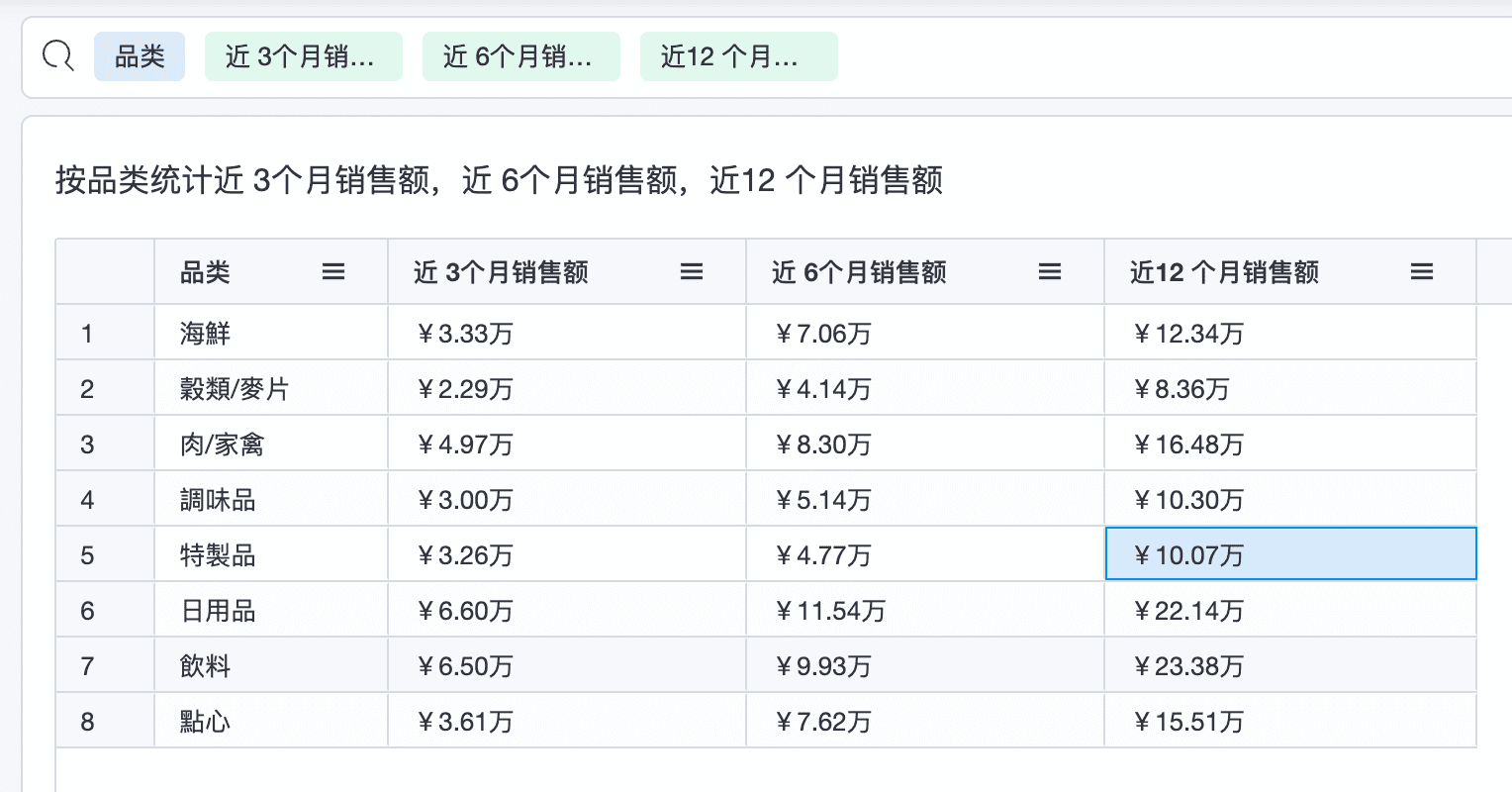

公式如下:
SUM_IF(
orders.order_date = LAST_MONTHS(3),
order_details.quantity * order_details.unit_price
),
SUM_IF(
orders.order_date = LAST_MONTHS(6),
order_details.quantity * order_details.unit_price
),
SUM_IF(
orders.order_date = LAST_MONTHS(12),
order_details.quantity * order_details.unit_price
)
2.1 统计每个品类的复购率
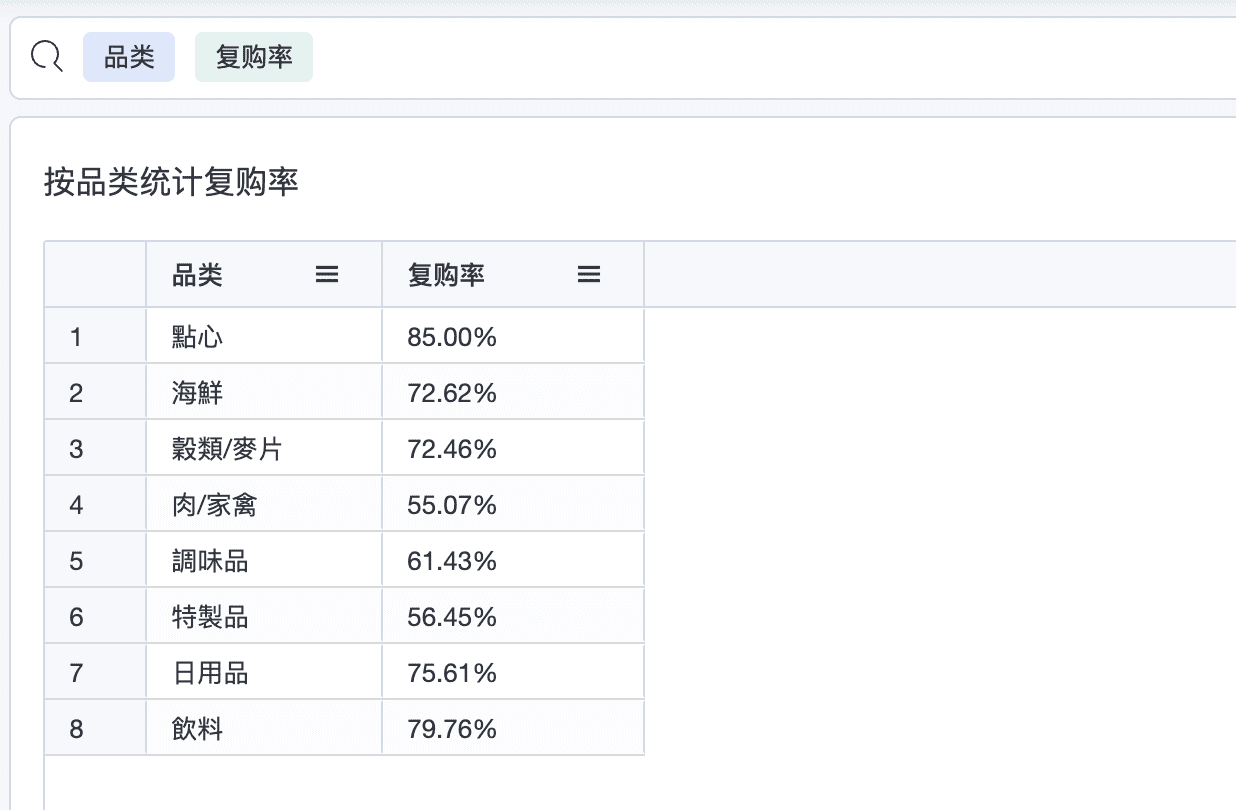

公式如下:
COUNT_IF(
GROUP_COUNT(orders.order_id, customers.customer_id, orders.order_date = LAST_MONTH(3)) > 1
) / COUNT(customers.customer_id) * 100
过滤聚合表达式内可以嵌套其它聚合函数,上述公式中 GROUP_COUNT 运算表达式的语义为:统计最近3 个月内订单数量大于 1 的客户数量。 整个表达式表达的语义为 "最近3 个月购物超过2 次的客户数量 / 总客户数量 * 100"
2.2 按客户所在城市统计牛奶销售占比
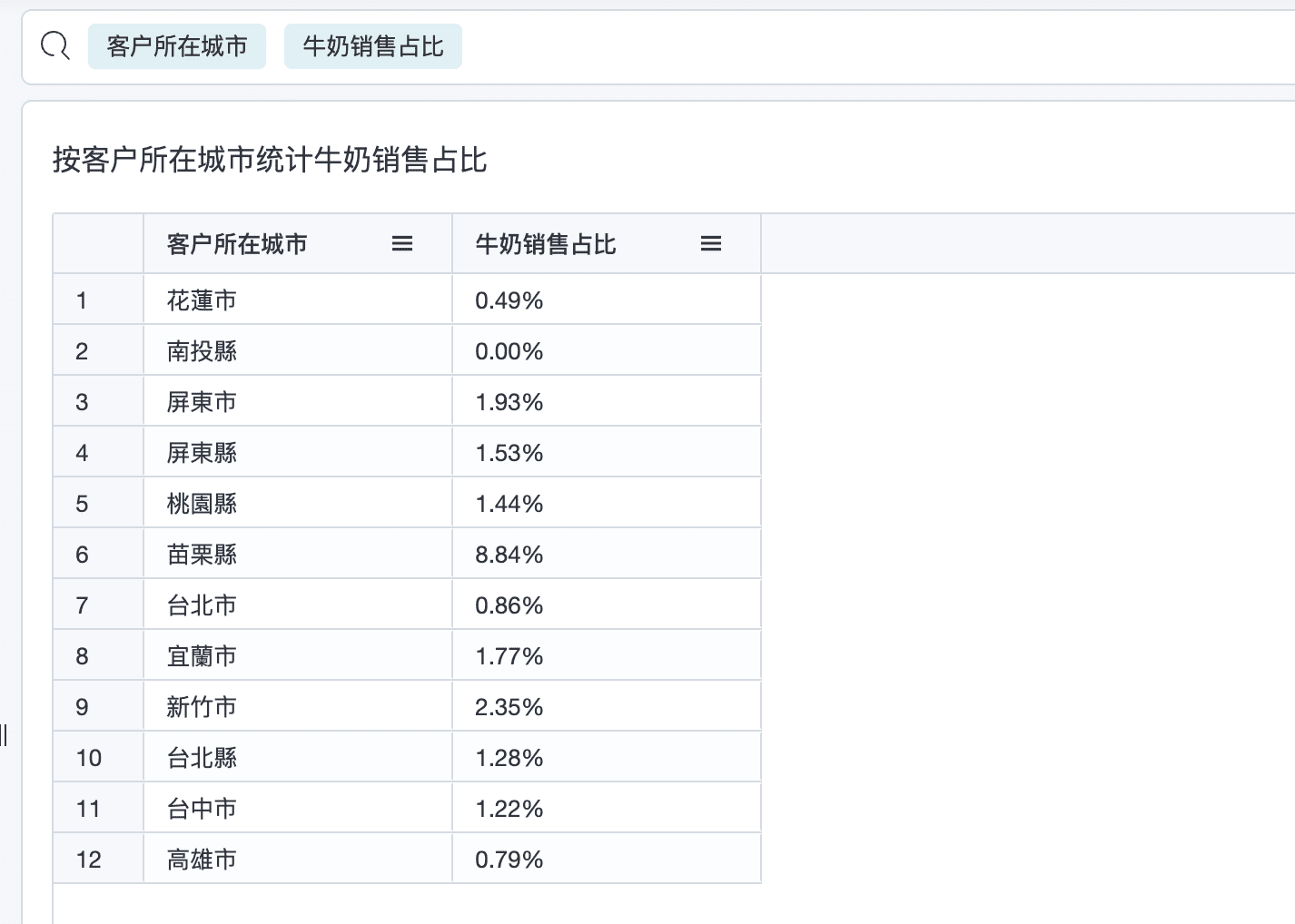

公式如下:
SUM_IF(
products.product_name = '牛奶',
order_details.quantity * order_details.unit_price
) /
SUM(order_details.quantity * order_details.unit_price) * 100
3. 分组聚合函数
分组聚合函数实际上是将函数内的参数组合成一个子查询,然后再与外部查询进行连接,从而实现不同维度的数值拉平至同一行进行运算,连接条件和分组条件, 依据同时投影的其它函数或列动态计算。分组聚合函数通常不会直接投影,而是与其它维度聚合后的数值运算后再投影。
3.1 统计每年,每品类的月均销售额
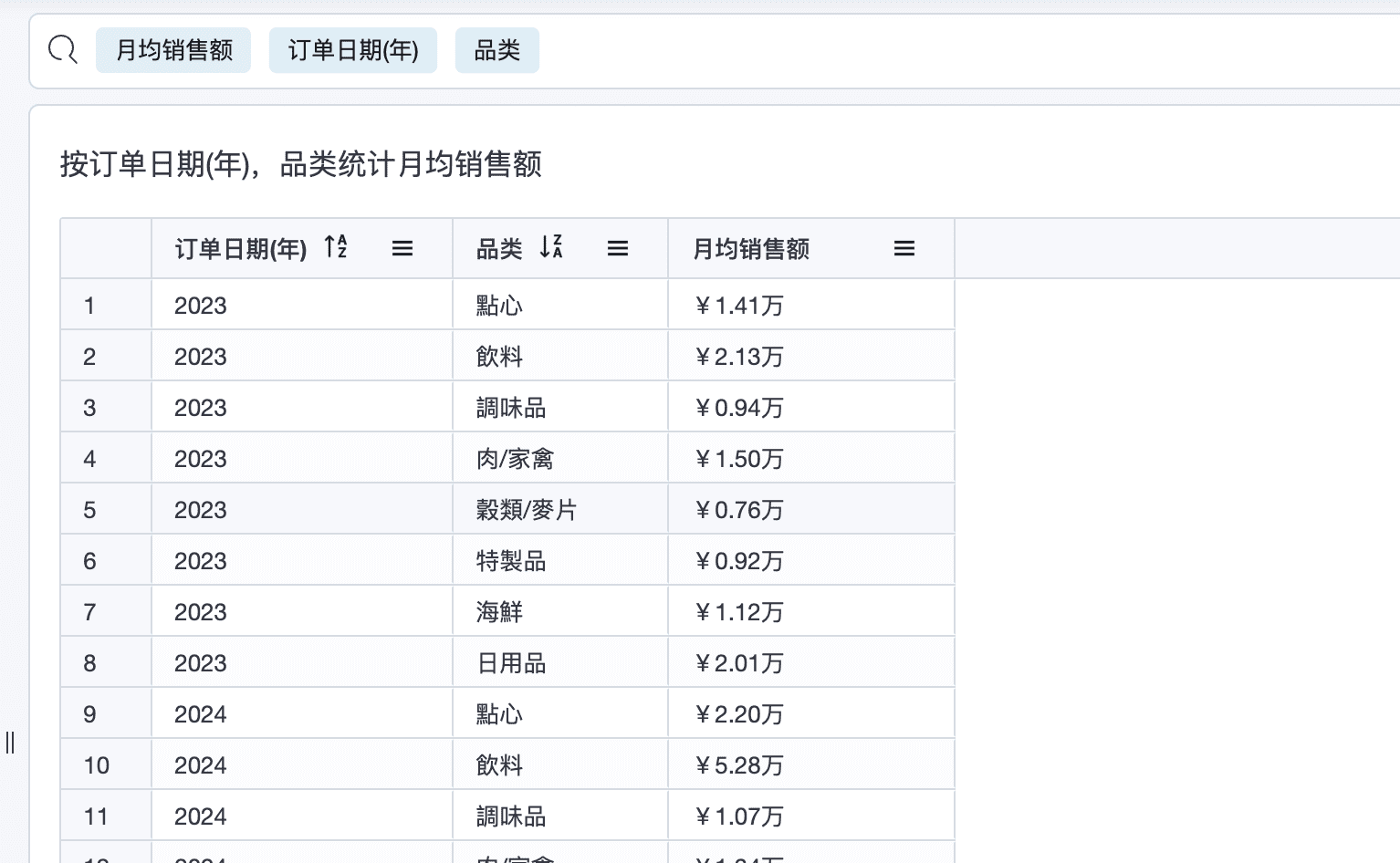
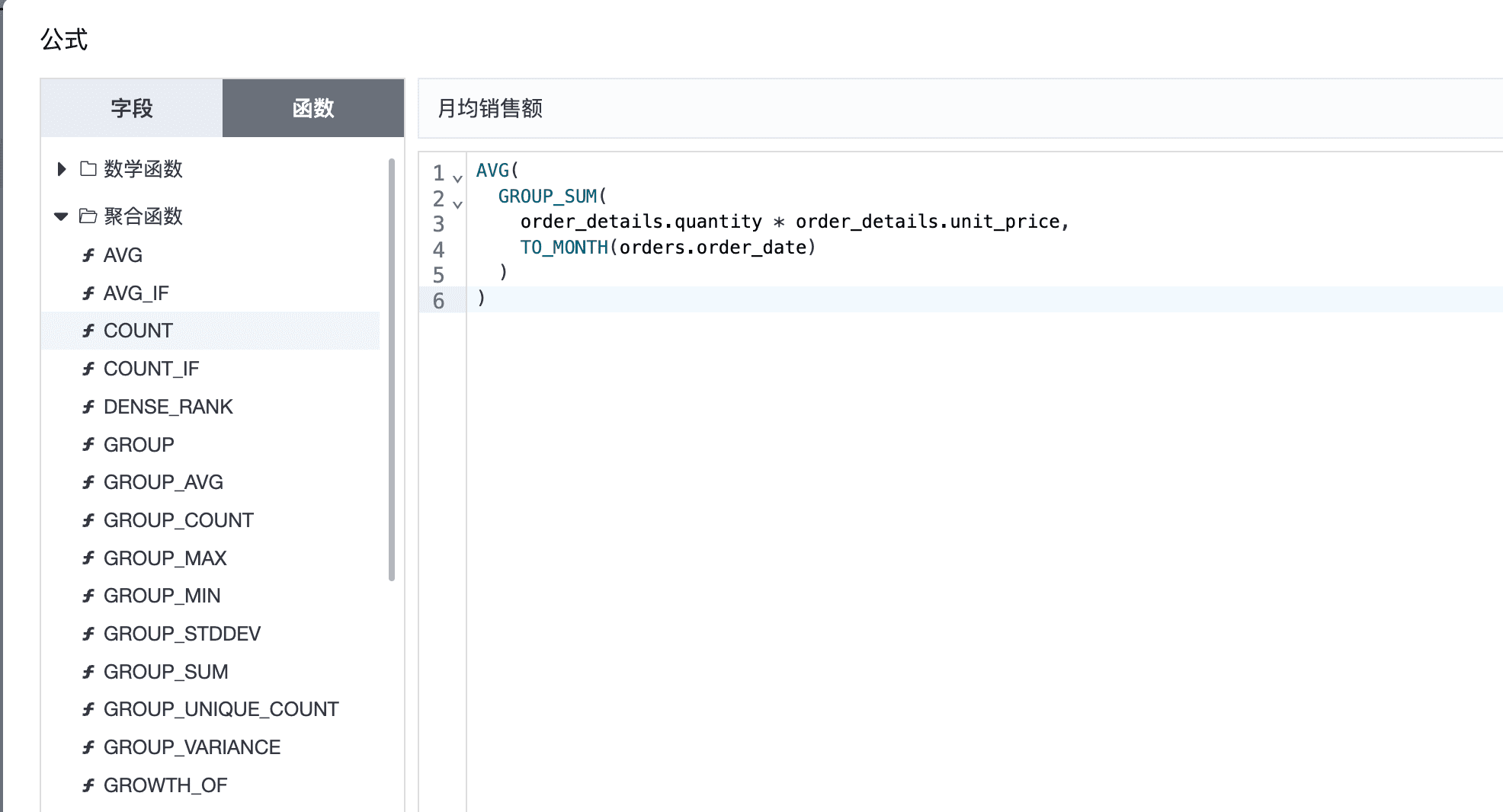
3.2 按品类,商品统计销售额,销售额占比,销售额品类占比
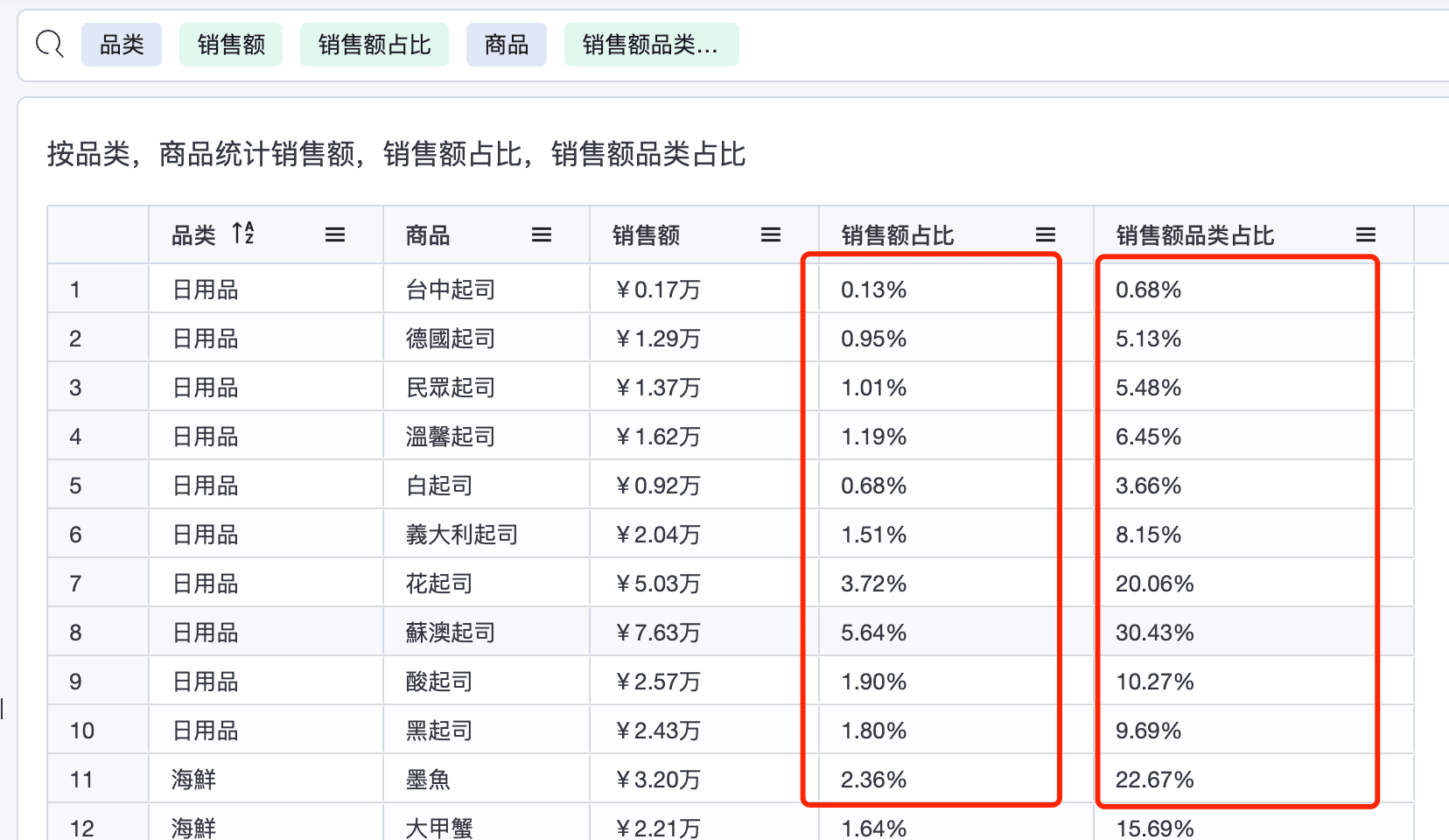

SUM(
order_details.quantity * order_details.unit_price
) /
GROUP_SUM(
order_details.quantity * order_details.unit_price,
categories.category_name
) * 100
3. 领域函数
领域函数是基于不同业务领域的数据分析方法的一种抽象,这些函数通常是为了解决特定领域中的业务问题而设计的,提供了对特定业务逻辑的支持。 领域函数的目的是简化数据分析的复杂性,使分析人员能够更轻松地处理特定领域的数据。领域函数虽然具备了领域特性,但依然属于高度抽象的聚合函数, 本质上封装的是数据分析方法,不同与PowerBI 封装的财务函数,过度贴合业务。
3.1 客户数量与销售额的环比统计
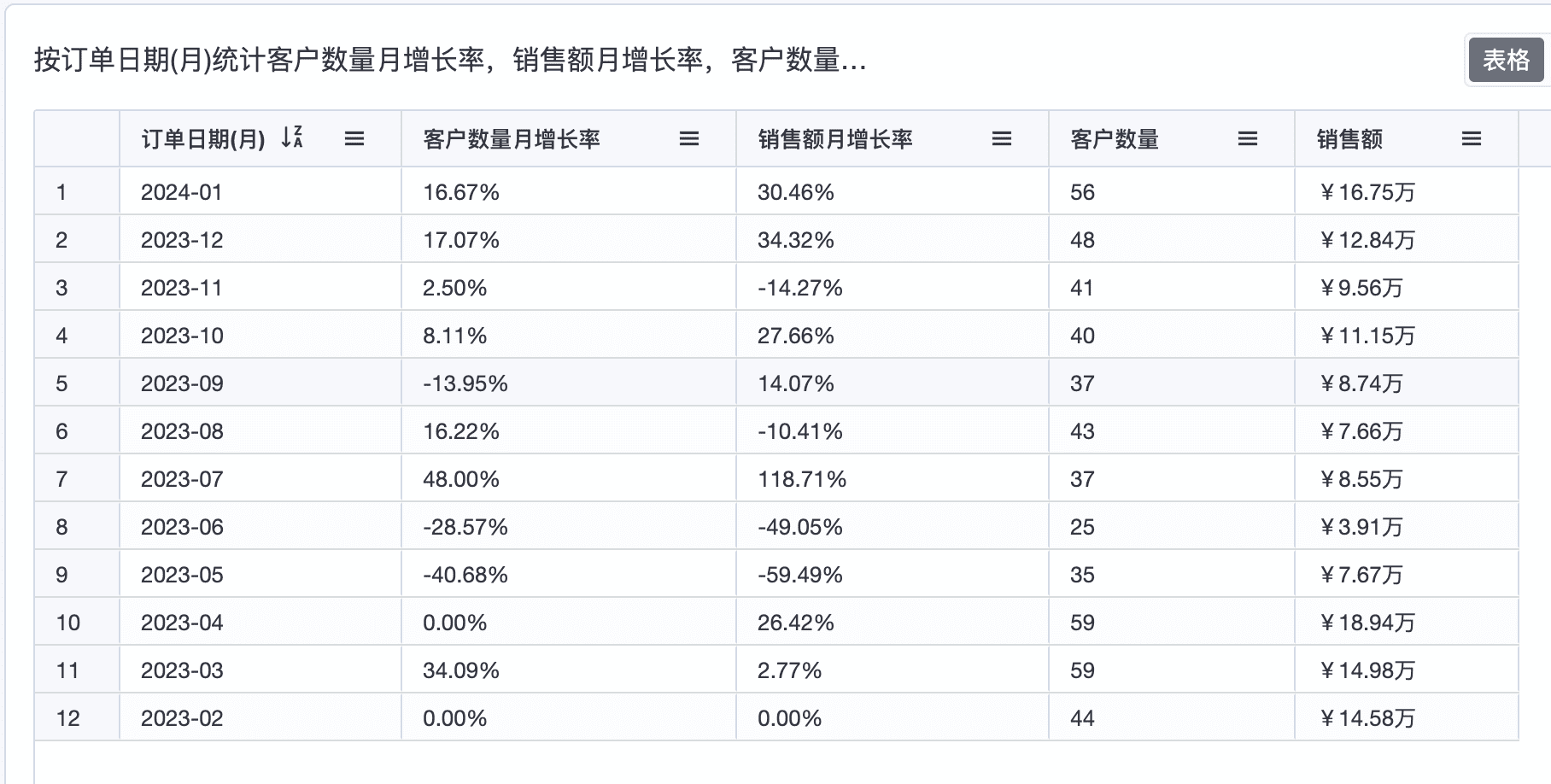

GROWTH_OF(
SUM(order_details.quantity * order_details.unit_price),
orders.order_date
)
GROWTH_OF(
COUNT(customers.customer_id),
orders.order_date
)
3.2 客户画像
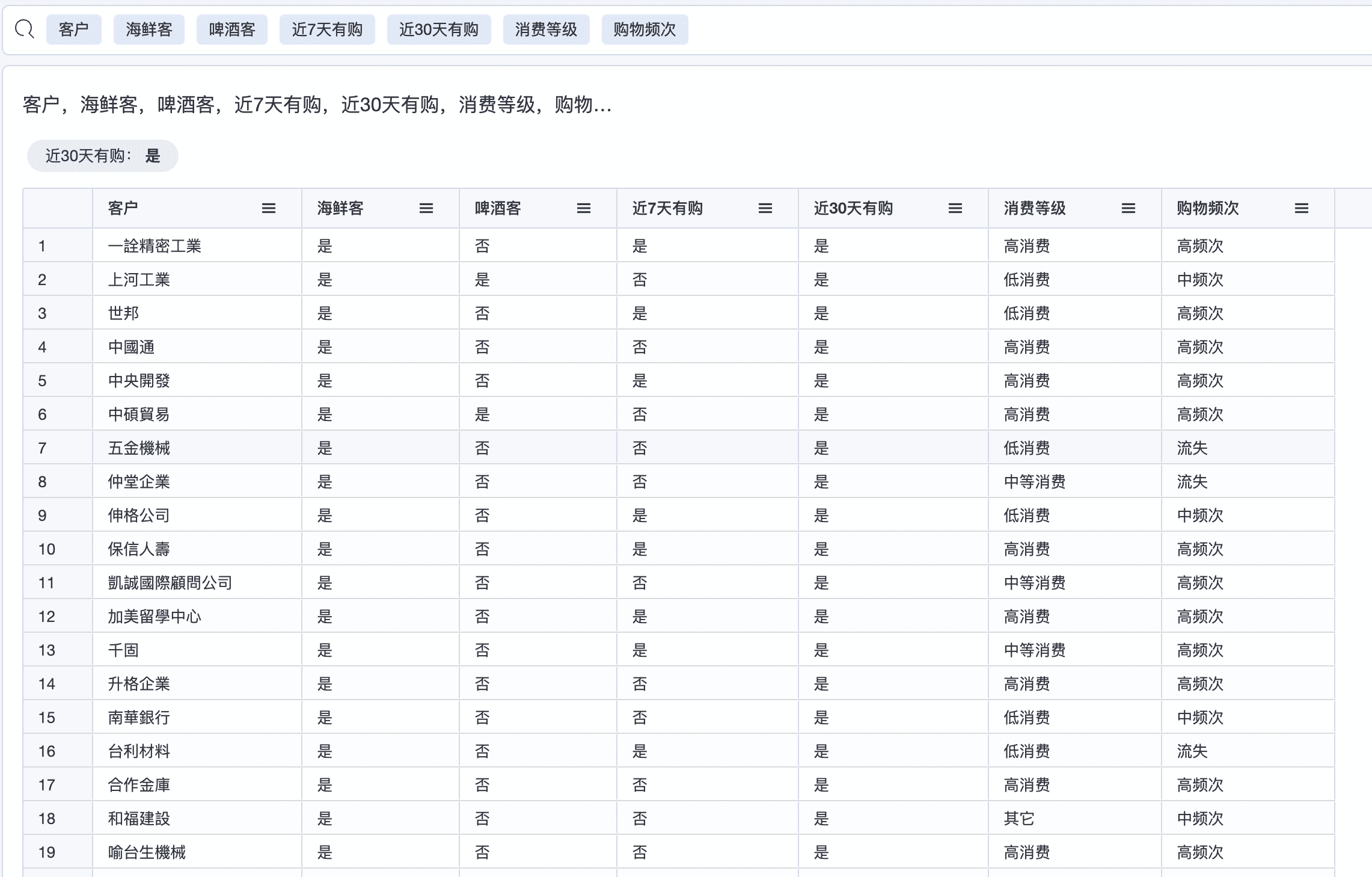

SEGMENT(
CASE
WHEN COUNT_IF(categories.category_name IN ('海鮮')) > 0 THEN '是' ELSE '否'
END,
customers.customer_id
)
SEGMENT(
CASE
WHEN COUNT_IF(orders.order_date = LAST_DAYS(30)) > 0 THEN '是' ELSE '否'
END,
customers.customer_id
)
SEGMENT(
CASE
WHEN COUNT(orders.order_id) > 5 THEN '高频次'
WHEN COUNT(orders.order_id) LBETWEEN 2 AND 5 THEN '中频次'
WHEN COUNT(orders.order_id) = 1 THEN '低频次'
ELSE '流失'
END,
customers.customer_id,
orders.order_date = LAST_MONTHS(3)
)
SEGMENT(
CASE
WHEN SUM(order_details.quantity * order_details.unit_price) > 10000 THEN '高消费'
WHEN SUM(order_details.quantity * order_details.unit_price) LBETWEEN 5000 AND 10000 THEN '中等消费'
WHEN SUM(order_details.quantity * order_details.unit_price) LBETWEEN 1000 AND 5000 THEN '低消费'
ELSE '其它'
END,
customers.customer_id,
orders.order_date = LAST_MONTHS(3)
)