
在介绍Agile Query 前,先简单介绍一下大数据(详细介绍请参考文章中的链接)。大数据的概念应该是2010 年左右在国外兴起的,国内也同步兴起,网络上有很多关于大数据的定义,包括:百度百科、 Oracle 等,但总觉得这些定义不是很准确,单纯的以数据体积和复杂程度来定义是远远不够的, 我尝试从数据计算的角度,补充一下大数据的定义:
微观视角: 数据在业务决策过程中的使用频率越来越高,分析视角从传统的宏观统计,不断地向更细粒度转变,参与计算的数据体量也会不断的增加, 导致看似很小的数据量,经过关系运算后,也会变得庞大,同时分析维度组合不断地切换,也会导致预计算变得越来越困难。
背景
数据分析相关的软件产品,对于企业来说并非刚性产品,但随着企业规模不断发展,对数据分析软件的依赖性会越来越强,最终会成为不可替代的工具。 不同行业对数据分析类软件的依赖程度各有不同。金融、保险和零售行业应该是最早采用数据分析的行业,而其他行业也跟随数字化转型的口号,纷纷采购了数据分析相关软件。 然而,实际产生的价值却因行业特性而异。目前数据分析类软件产品,主要包括以下几大类:
- 数据可视化:主要以开源BI 系统为主,这类系统通常需要数据工程师编写大量SQL,
数据准备的研发投入比较大。 - 数据再加工:主要以国内通用型商用BI 系统为主,通常支撑的数据体量过小,大数据量计算时,还是需要编写大量SQL。
- 行业定制:主要以国内大数据公司的平台为主,为细分行业(例如:用户行为、游戏等)定制的数据分析系统,个性化分析需求支持不足。
大数据分析类软件经过十数年的发展,也衍生出很多概念,例如:数据血缘、指标平台、数据集市和预计算等,这些概念是和一个时代的技术发展紧密相关, 也是一些公司为了解决一些特定问题的市场化包装,并起了一些看似很专业的名词。但随着技术的发展,这些也就显得冗余,经不起迭代,也只能是技术发展长河中的小插曲。
随着MPP 型数据库的快速发展,大数据量的计算方法逐渐向SQL 这个古老的语言倾斜,数据加工层可以变得很薄且抽象程度也可以很高,个性化查询需求变得容易实现。 但SQL 的编程属性比较弱,工程化实施变得复杂,整个行业可能会往两个方向发展,一个就是类似ObjectiveSql 这类项目, 提供一个可编程的SQL 框架,另一个方向就是设计一个更高级的分析语言,屏蔽一些关系计算的底层逻辑,让数据工程师或分析师将注意力聚焦在自身业务上, Agile Query 便是第二种方案,底层由FlatQL 编译器结合关系描述,将查询语言编译成SQL Dialect,并基于数据统计方法,设计了一系列高级聚合函数, 对外屏蔽了SQL 底层的关系计算逻辑。
关系计算的反直觉模式
关系计算的核心是笛卡尔乘积,但笛卡尔乘积形成的二维表格,却是反人类直觉的,如下图所示(为简化我们忽略连接条件):

note
上图的计算结果中 R1 表和 R2 表中的数据被翻倍了,无论是左连接、右连接、还是其它连接方式,得到的结果总会违反人类直觉上的认知,如果对 R1
表中的数据进行 SUM, COUNT 或其它方式聚合,总会得到错误的结果,这就是数据工程师的主要工作,手工调整数据输出,使其符合人类直觉。
指标和维度的自由组合
行业不同,指标和维度的设计也不同,分析的场景不同,指标和维度的组合也不同。在各行各业快速发展的过程中,一个固化的数据分析系统,总会跟不上企业发展的步伐, 如果按需定制,也需要不断投入时间和货币成本。指标和维度的自由组合是个性化数据分析的必要条件,但自由组合后,就需要对笛卡尔乘积进行统一方式的处理, 这也就是Agile Query 所要解决的核心问题之一。
Agile Query 系统结构
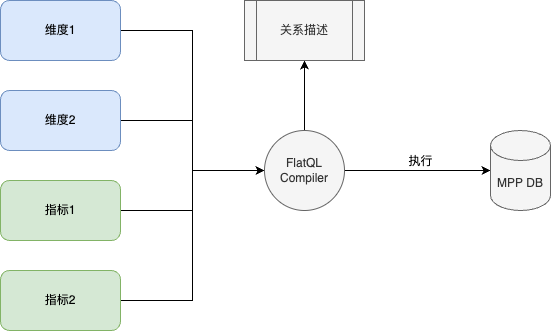
note
- 图中定义的维度和指标,可以是数据库中的原生Column,也可以是FlatQL 的函数,预定义的函数或列可以自由组合,由FlatQL Compiler 动态识别分析意图
- 表之间的关系描述为预先定义,FlatQL Compiler 动态识别表关系间的过度计算,按人类自然直觉调整SQL,输出符合人类认知的二维数据
- FlatQL Compiler 会根据不同的MPP 型数据库,生成不同的SQL
Agile Query 核心技术
- 分析意图识别算法:系统动态识别用户输入的关键字语义,并依据基础数据分析方法,结合关系计算,推理出符合人类认知的二维数据,并结合智能可视化方法, 为用户提供不视角的数据分析方法
- 过度计算识别算法:系统基于关系描述和用户输入的关键字语义,动态计算出查询涉及的表,并依据关系定义推理出所有过度计算的关系, 并以合并子查询的方式生成SQL
- 查询优化算法:系统会基于最优化规则自动合并原生查询,调整连接顺序,优化查询过程